声明:本文来源于微信公众号 新智元(ID:AI_era),作者:新智元,授权站长之家转载发布。
【新智元导读】近日,Picsart AI Resarch等团队联合发布了StreamingT2V,可生成1200帧、2分钟的视频,一举超越Sora。同时,StreamingT2V作为开源世界的强大组成部分,可以与SVD和animatediff无缝兼容。
120秒超长AI视频模型来了!不仅比Sora长,还免费开源!
近日,Picsart AI Resarch等团队联合发布了StreamingT2V,可生成1200帧、2分钟的视频,质量也很好。

论文地址:https://arxiv.org/pdf/2403.14773.pdf
试用Demo:https://huggingface.co/spaces/PAIR/StreamingT2V
开源代码:https://top.aibase.com/tool/streamingt2v
而且,作者说,两分钟不是模型的极限,就像Runway之前的视频可以延长一样,StreamingT2V理论上可以实现无限长。

在Sora之前,Pika、Runway、Stable Video Diffusion(SVD)等待视频生成模型,一般只能生成几秒钟的视频,最多延长到十秒以上,

Sora一出,60秒的时间直接持续秒杀Runway的一群模型CEO Cristóbal Valenzuela当天发推说:比赛开始了。

——不,120秒的超长AI视频来了。
虽然Sora的统治地位不能马上动摇,但至少要在时间上扳回一城。
更重要的是,作为开源世界的强大组成部分,StreamingT2V可以兼容SVD和animatediff等项目,更好地促进开源生态的发展:

从发布的例子来看,目前兼容的效果还是有点抽象,但是技术进步只是时间问题,卷起来才是最重要的~
总有一天我们可以用它「Sora开源」,——你说是吧?OpenAI。
目前,StreamingT2V已在GitHub开源,同时还在Hugingface上提供免费试用,等不及了,小编马上开始测试:
不过貌似服务器负荷太高,以上这个不知道是不是等待时间,反正小编也没能成功。
目前,试用界面可以输入文本和图片两个提示,后者需要在下面高级在选项中打开。
在两个生成按钮中,Faster Preview是指分辨率较低、持续时间较短的视频。

于是小编转向另一个测试平台(https://replicate.com/camenduru/streaming-t2v),以下是文字提示,最终获得测试机会:
A beautiful girl with short hair wearing a school uniform is walking on the spring campus
但也许是因为小编的要求比较复杂,所以产生的效果有点吓人,你可以根据自己的经验来尝试。
以下是huggingface上给出的一些成功案例:

StreamingT2V

「世界名画」
Sora的诞生带来了巨大的轰动,使Pika在前一秒闪闪发光、Runway、SVD等模型直接变成「前Sora时代」的作品。
但正如StreamingT2V的作者所说,pre-Sora days模型也有自己独特的魅力。

StreamingT2V是一种先进的自回归技术,可以在没有任何停滞的情况下创建运动动态丰富的长视频。
它保证了整个视频的时间一致性,与描述性文本紧密对齐,保持了高帧级图像的质量。
从现有文本到视频扩散模型,主要集中在高质量的短视频生成(通常是16或24帧)上。当直接扩展到长视频时,会出现质量下降、僵硬或停滞等问题。

人工智能生成视频
通过引入StreamingT2V,视频可以扩展到80、240、600、1200帧,甚至更长,并且有一个平滑的过渡,在一致性和运动性方面优于其它模型。
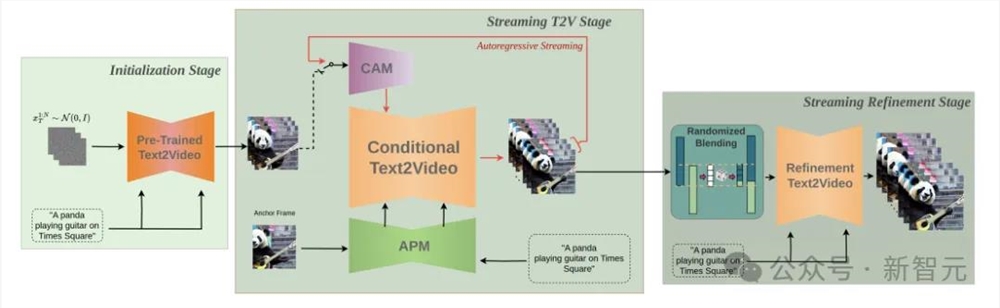
StreamingT2V的关键组件包括:
(i)称为条件注意模块(CAM)短期记忆块,根据前一块中提取的特点,通过注意机制调整当前一代,实现一致的块过渡;
(ii)称为外观保留模块(APM)它来自长期记忆块第一从视频块中提取高级场景和对象特征,防止模型忘记初始场景;
(iii)一种随机混合的方法可以自动将无限长的视频返回到应用视频增强器中,而不会出现块之间的不一致性。
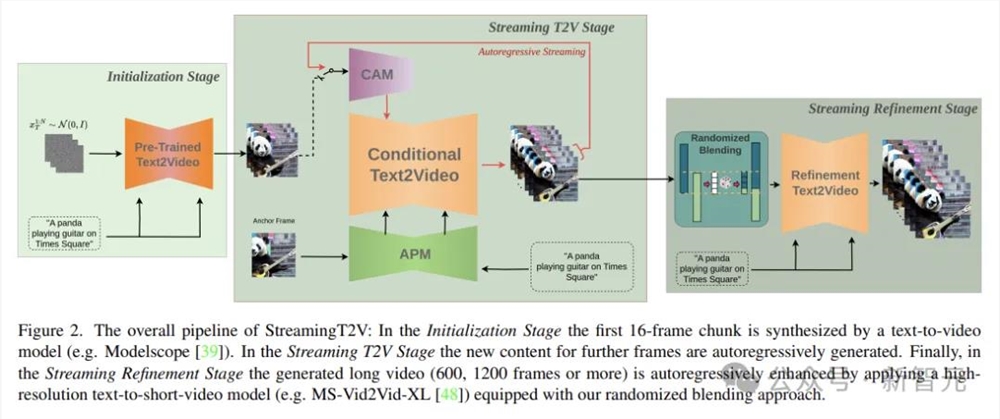
以上是StreamingT2V的整体流水线图。在初始化阶段,第一由文本到视频模型合成的16帧。流式处理 T2V 在这个阶段,更多帧的新内容将自动回归生成。
最后,在流优化阶段,通过将高分辨率文本应用到短视频模型,并配备上述随机混合方法生成的长视频(600)、1200帧或更多帧会自动回归增强。

上图显示了StreamingT2V方法的整体结构:条件注意模块(CAM)外观保留模块作为短期记忆(APM)扩展到长期记忆。CAM使用帧编码器在前一块上扩散视频模型(VDM)进行条件处理。
CAM的注意力机制保证了块与视频之间的平滑过渡,同时具有高运动量。
从锚定帧中提取APM高级将图像特征注入VDM的文本交叉注意力中,有助于在视频制作过程中保留对象/场景特征。
研究人员首先预先培训一个文本到(短)视频模型(Video-LDM),然后使用CAM(前一块的一些短期信息)对Video-LDM进行自回归调整。
CAM由一个特征提取器和一个特征注入器组成,集成到Video-LDM的UNet中。特征提取器使用逐帧图像编码器 E。
对于特征注入,作者使UNet中的每一个通过交叉注意力产生的CAM相应特征,远程跳跃连接。
CAM使用前块的最后一个Fconditional帧作为输入,交叉注意力可以将基本模型的F帧调整为CAM。
相比之下,稀疏编码器使用卷积注入特征,因此需要额外的F − Fzero值帧(和掩码)作为输入,以将输出添加到基本模型的F帧中。这将导致SparseCtrl的输入不一致,导致视频严重不一致。
自回归视频生成器通常会忘记初始对象和场景特征,从而导致严重的外观变化。
为了解决这个问题,外观保留模块(APM)利用第一固定锚定帧中包含的信息可以整合长期记忆。这有助于维护视频块生成之间的场景和对象特征。

作者建议APM平衡锚定帧的引导和文本指令的引导:
(i)将锚定帧的CLIP图像标记与文本指令中的CLIP文本标记混合,使用线性层将编辑图像标记扩展到K =8, 将文本和图像编码连接到标记维度,并使用投影块;
(ii) 将权重引入每个交叉注意力层α∈R(初始化为0)使用加权总和x的键和值来执行交叉注意力。
为了进一步提高从文本到视频结果的质量和分辨率,这里使用从文本到视频模型的高分辨率(1280x720)。(Refiner Video-LDM)24帧块自动回归增强视频的生成。
使用文本到视频模型作为24帧块的细化器/增强器,通过向输入视频块添加大量噪声,并使用文本到视频扩散模型去除噪声来完成。
然而,独立增强每个块的简单方法会导致不一致的过渡:

作者通过在连续块之间共享噪音,并使用随机混合来解决这一问题。

上图是Dynamicrafter-XL与StreamingT2V的视觉对比,使用相同的提示。
X-T切片可视化显示,DynamiCrafter-XL有严重的块不一致和重复运动。相比之下,StreamingT2V可以无缝过渡和持续发展。
现有的方法不仅容易出现时间不一致和视频停滞,还会受到物体外观/特征变化和视频质量下降的影响(如下图中的SVD)。

原因是他们忽略了自回归过程的长期依赖,因为他们只调整了前一块的最后一帧。
StreamingT2V在上图的视觉比较中生成长视频(80帧长度,自回归生成视频),不会出现运动停滞。
AI长视频能做什么?
每个家庭都在制作卷视频,最直观的应用场景,可能是电影或游戏。

用AI生成的电影片段(Pika,Midjourney,Magnific):

Runway甚至举办了AI电影节:

但另一个答案是什么呢?
世界模型

长视频创造的虚拟世界是Agent和人形机器人最好训练环境,当然前提是足够长,足够真实(符合物理世界的逻辑)。
也许在未来的某一天,它也将是我们人类的生存空间。
Copyright © 2013-2025 bacaiyun.com. All Rights Reserved. 八彩云 版权所有 八彩云(北京)网络科技有限公司 京ICP备2023023517号
本站文章全部采集于互联网,如涉及版权问题请联系我们删除.联系QQ:888798,本站域名代理为阿里云
