声明:本文来自微信公众号“量子位”(ID:QbitAI),作者:关注前沿科技,授权站长之家转载发布。
北大与字节联手做了个大的:
提出图像生成新范式,从预测下一个token变成下一个token预测下一级分辨率,超越Sora核心组件Diffusion的效果 Transformer(DiT)。
而且代码开源,短短几天就赢得了1.3k标星,登上了GitHub趋势榜。

具体的效果是什么?
在实验数据中,这个名字叫做VAR(Visual Autoregressive Modeling)不仅图像生成质量超过Dit等传统SOTA的新方法,推理速度也提高了20+倍。
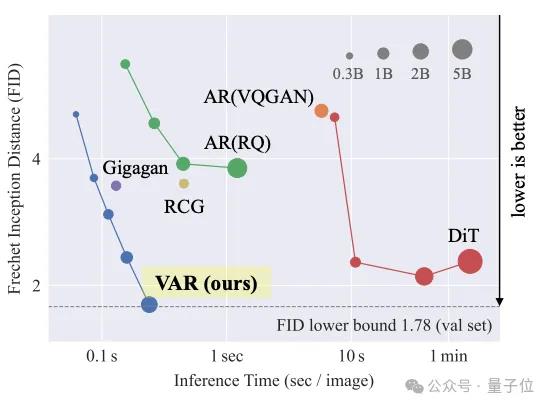
这也是自回归模型首次在图像生成领域击败Dit。
直观感觉上,话不多说,直接看图片:

值得一提的是,研究人员还在VAR上观察到大语言模型的Scaling Laws和零样本任务泛化。
在线论文代码引发了许多专业讨论。
一些网民说他们很惊讶,突然觉得其他扩散架构的论文有点无聊。

其他人则认为,这是一种更便宜的通往Sora的潜在方式,计算成本可以降低一个甚至多个数量级。

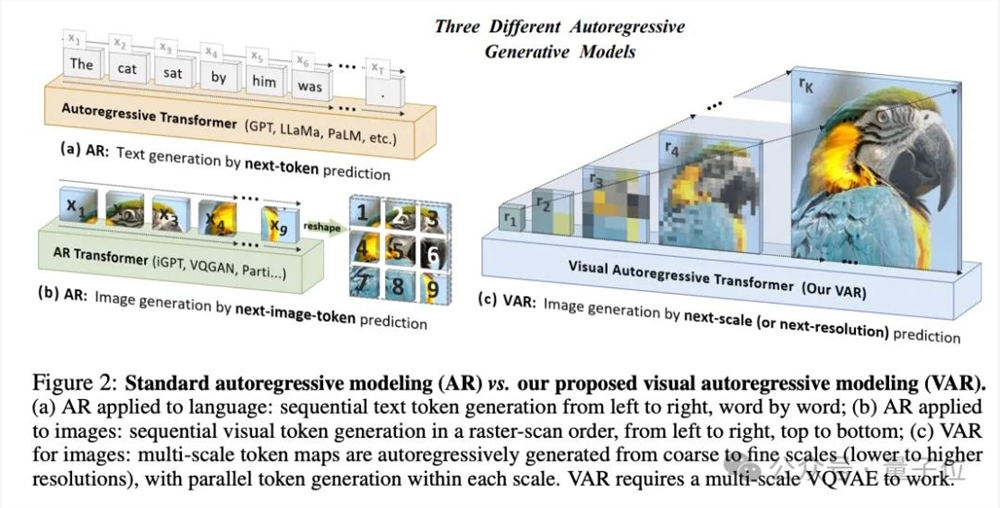
简单来说,VAR的核心创新就是用预测下一级分辨率,替代了预测下一个token传统的自回归方法。
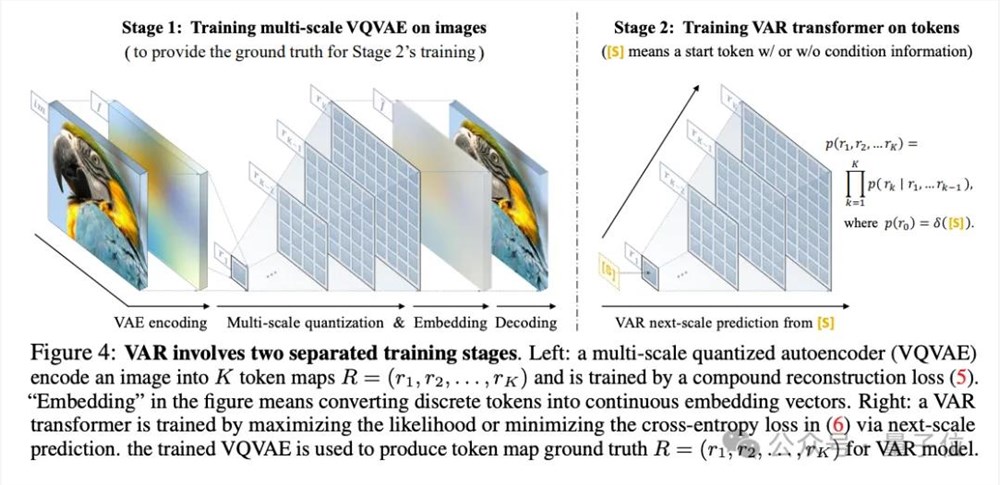
VAR训练分为两个阶段。
第一在这个阶段,VAR引入了多尺度的离散,用VQ-VAE将连续图像编码成一系列离散的token map,每一个token map有不同的分辨率。
第二阶段主要是VAR 通过预测更高分辨率的图像,Transformer的训练可以进一步优化模型。具体流程如下:
从最低分辨率(如1×1)token map开始预测下一级分辨率(例如4×4)完整的token map,并以此类推,直到生成最高token的分辨率 map(比如256×256)。预测每个尺度的token 在map中,基于transformer的模型将考虑之前所有步骤生成的映射信息。
VQ-VAE模型在第二阶段发挥了重要作用:为VAR提供了“参考答案”。这有助于VAR更准确地学习和预测图像。
此外,VAR是并行预测所有位置的token,而不是线性预测,大大提高了生成效率。
研究人员指出,VAR更符合人类视觉感知从整体到局部的特点,并能保留图像的局部空间。
从实验结果来看,VAR在图像生成质量、推理速度、数据效率和可扩展性等方面都超过了DIT。
Imagenet256×VAR将FID从18.65降至1.8,IS从80.4升至356.4,显著改善了自回归模型基线。
注:FID越低,生成图像的质量和多样性就越接近真实图像。
在推理速度方面,与传统的自回归模型相比,VAR的效率提高了20倍左右。Dit消耗的时间是VAR的45倍。
在数据效率方面,VAR只需要350个训练周期(epoch),远远少于DiT-XL/2的1400个。

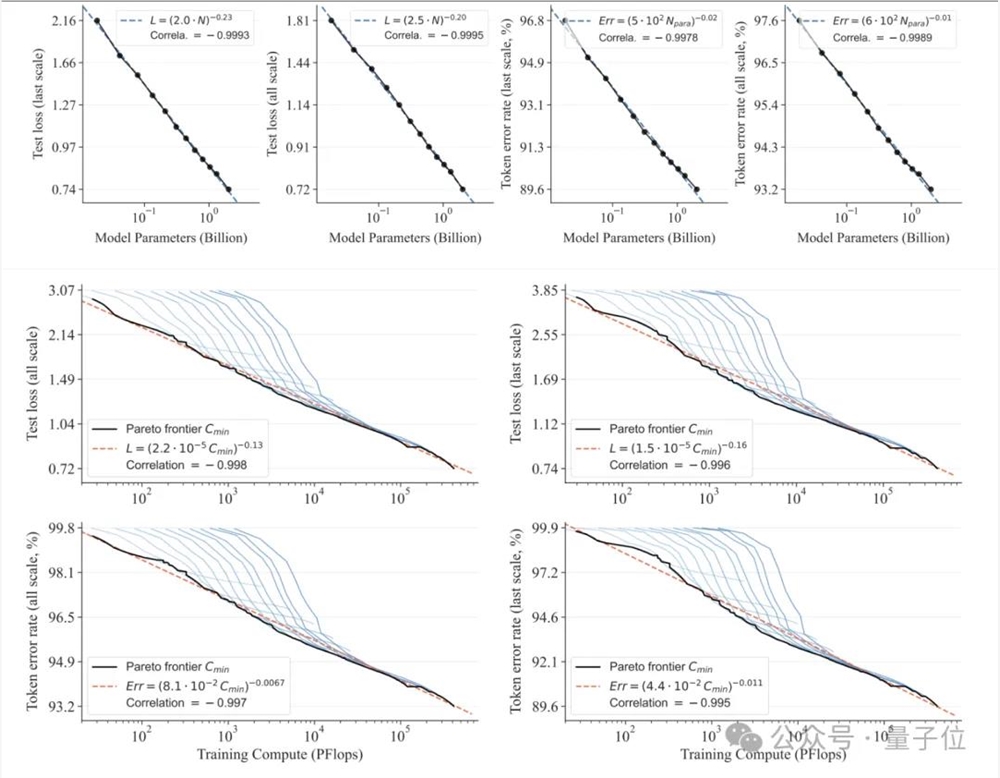
在可扩展性方面,研究人员观察到VAR有类似于大语言模型的Scaling Laws:伴随着模型尺寸和计算资源的增加,模型性能不断提高。
此外,VAR在图像修复、扩展和编辑等下游任务的零样本评估中表现出了出色的泛化能力。

在GitHub仓库中,推理示例,demo、模型权重和训练代码已经上线。
然而,在更多的讨论中,一些网民提出了一些问题:
VAR不如扩散模型灵活,分辨率存在扩展问题。

VAR的作者来自字节跳动AI 北大王立威团队Lab和Lab。
本科毕业于北航的田柯宇,目前是北京大学CS研究生,师从北京大学信息科学技术学院教授王立伟。2021年开始字节AI Lab实习。
论文通讯作者是字节跳动AI Lab研究员袁泽环和王立威。
袁泽环于2017年博士毕业于南京大学,目前专注于计算机视觉和机器学习。王立伟从事机器学习研究20多年,是首届“优秀青年”获得者。
项目负责人是字节跳动广告生成人工智能研究负责人Yi jiang。他毕业于浙江大学,目前的研究重点是视觉基础模型、深度生成模型和大语言模型。
参考链接:
[1]论文:https://arxiv.org/abs/2404.02905
[2]项目主页:https://github.com/FoundationVision/VAR
Copyright © 2013-2025 bacaiyun.com. All Rights Reserved. 八彩云 版权所有 八彩云(北京)网络科技有限公司 京ICP备2023023517号
本站文章全部采集于互联网,如涉及版权问题请联系我们删除.联系QQ:888798,本站域名代理为阿里云
