声明:本文来源于微信公众号 量子位(ID:QbitAI),作者:衡宇,授权站长之家转载发布。
好啊,不愧是OpenAI最新旗舰,打开各种社交软件,GPT-4o所有的上手测试都在我的首页被推到我的首页。
请!看!
这是使用GPT-4o,不到30秒,通过单个prompt生成完整的图表和统计分析。

在过去,在Excel里做这件事,不要花我们工人好一段时间?
下图是网友用GPT-4o创建的四腿桌三维模型STL文件,不到20s。

牛哇牛哇!
毕竟GPT-4o能力横跨听、说、看,主要是因为免费啊!
就像网友总结的那样,现在每个用户都可以通过AI和简单的Prompt生成伟大的东西。
然而,有必要探索“如何生成复杂结构的东西”。
让我们来看看网民们是如何无私地玩GPT-4o的——
一年一度的谷歌 I/O 开发者大会前24小时,OpenAI突袭发布GPT-4o。
“o“是Omni的缩写,意思是“全能”。
由于GPT-4o接受文本、音频和图像的任何组合作为输入,并生成文本、音频和图像输出,因此敢于命名。
在5月14日的OpenAI官方演示中,使用非常丝滑,甚至响应音频输入的速度也赶上了人类。
抱着“我不相信,除非我试试”的态度,网友们已经疯了。
首先,这个所谓的“爱因斯坦谜题”与我们小时候做的奥数题非常相似用于测试大模型的逻辑能力的。
题目背景如下:
在一条街上,有五栋房子喷了五种颜色。不同国籍的人住在每个房子里。每个人都喝不同的饮料,抽不同品牌的香烟,养不同的宠物。
提示:
(1)英国人住在红房子里。
(2)瑞典人养狗。
(3)丹麦人喝茶。
(4)白色房屋左侧隔壁有绿色房屋。
(5)绿屋主人喝咖啡。
(6)抽Pall 香烟的人养鸟。
(7)黄色房子的主人抽Dun Hill香烟。
(8)住在中间房子的人喝牛奶。
(9)挪威人居住第一间房。
(10)抽 Blends香烟的人住在养猫的人隔壁。
(11)养马人住抽Dun 隔壁是Hill香烟人。
(12)抽 Blue Master的人喝啤酒。
(13)德国人抽烟 Prince香烟。
(14)挪威人住在蓝色房子旁边。
(15)抽 Blends香烟的人有一个喝水的邻居。
问题来了,谁养鱼?谁住蓝色房子?
前几天网友在lmsys测试i-am-gpt2-bot(即在大型竞技场大杀特杀的神秘GPT-2),爱因斯坦的谜题无法解答——也没有其他人工智能能解决这个问题。
但是试一试,GPT-4o光速回答正确。
你可以自己测试(手动狗头)。

前脚刚看到OpenAI说GPT不能用来选股,没有参考意义。
后脚有网友在推特上发布了GPT-4o自动选股器,并配文:强得可怕!
具体来说,他利用GPT-4o自动将200多行选股指标改写成自动选股器、输出图和数据归档。
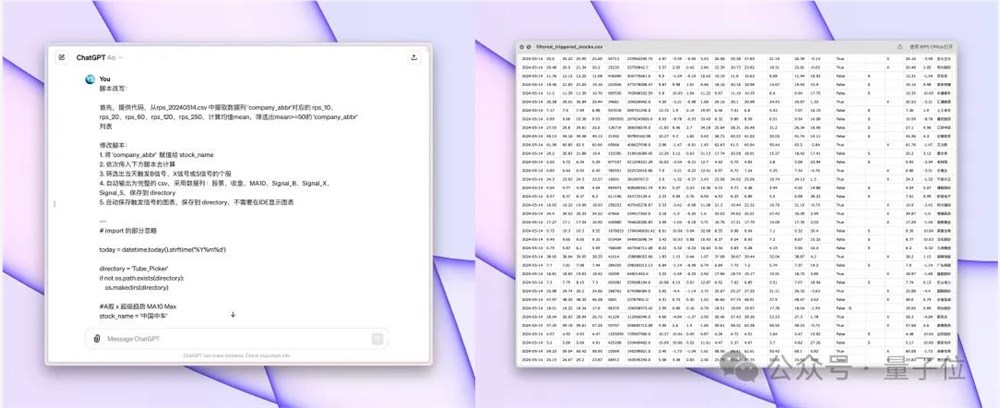
而且只需要一轮交互就能达到满意的效果,效率打GPT-4(哦,我打前辈自己)
据他说,GPT-4需要反复修改,处理100行以上的代码非常低效。
对此,网友的评价非常精辟:
如果能100%预测真的很完美!但如果预测不正确,最好不要预测...
也有网友试图用GPT-4o将写在纸上的原型转录为电脑中的初始HTML。
他白纸黑字是这样写的:
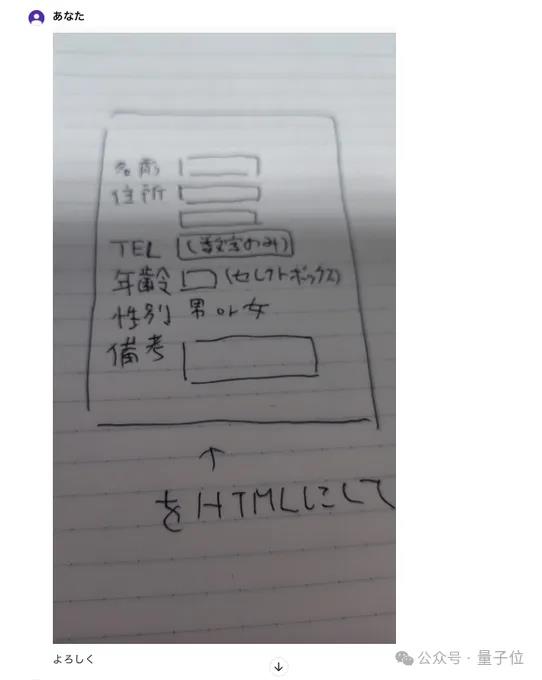
然后把这张照片喂给GPT-4o。
然后GPT-4o说:
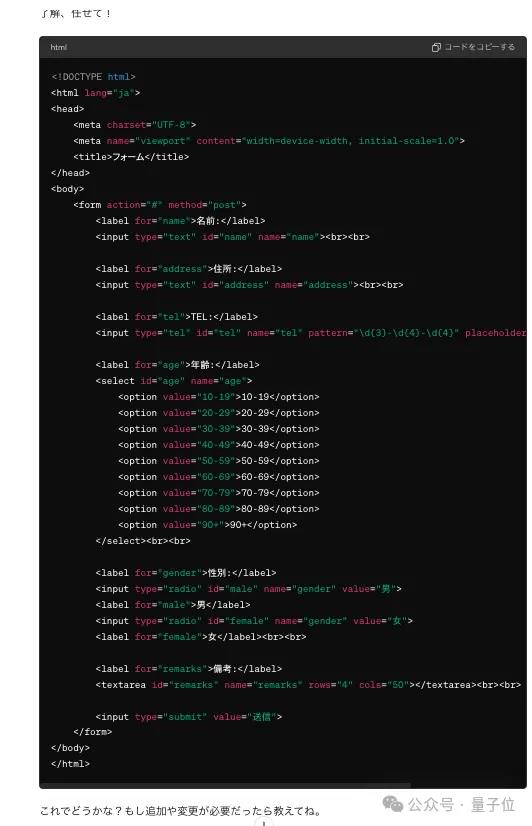
然后就得到了:
网友本人对吐出的结果非常满意,他兴奋地在推特上写道:
就像我们正在进行超越世界的对话一样,这真的是Soooooo Cool~

他不止一个,还有网友在Hacker。 News表示,他还可以使用GPT版本将原始动态数据动态转换为美丽的HTML布局。
制作低流量页面,如更改/审核日志,可节省大量开发时间,当数据结构发生变化时,HTML可以保持更新。
然而,尝试不是回归效果,因为GPT-4-Turbo有时几乎完全忽略了上下文和解释。
然而,一些网民说,GPT-4o的OCR能力也有点牛气
事情是这样的,他把这张照片扔给了GPT-4o。
怎么说呢,真的很密集,公司的logo有图像和文字,人类肉眼看有点难。

GPT-4o的结果让测试者自己感到惊讶,他说:“它不断地吐出图片中的内容,即使是人类也很难识别。”

旁观者纷纷发帖留言,无非是“以后用它的人和不用它的人的工作似乎会有很大的不同”“如果跟不上先进技术,就会落后”。
OpenAI再次让世界大吃一惊,谷歌坐不住了。
谷歌在今天凌晨的新闻发布会上带来了它Project Astra,它家的最新大型产品。
和GPT-4o一样,Project Astra可以写、听、看、说,也可以在几乎没有延迟的情况下与人类畅快交流。
不过Jim,英伟达科学家 Fan老师带头出来评论一下:
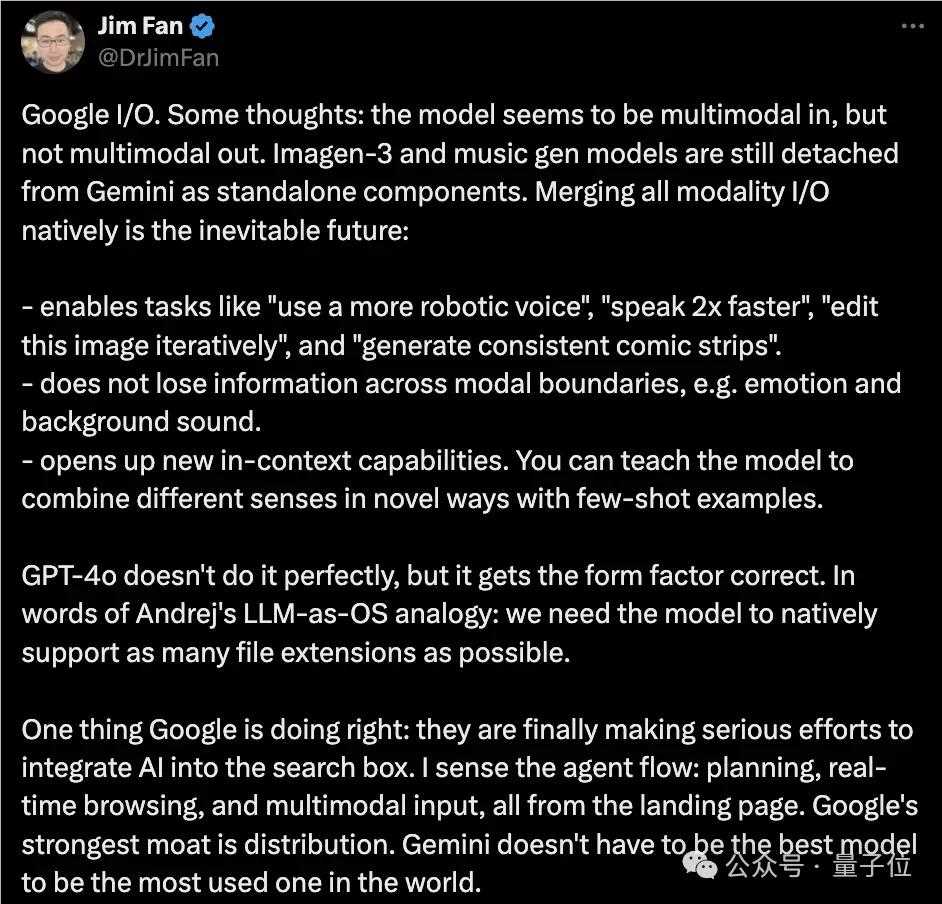
首先,谷歌似乎是多模态输入,而不是多模态输出。
Imagen-3和Google的图像生成模型仍然是一个独立的组件,没有融入其中。
他提到了自己的观点,那就是整合所有模式是不可避免的未来趋势,当然,他认为还有一些不可或缺的细节,具体如下。
使用任务选项,如“使用更机械化的声音”、“说话速度加快两倍”、“迭代编辑此图像”和“生成一致的漫画”;
跨模式的信息,如情感和背景声音,不会丢失。
开启新的上下文功能,您可以通过少量的例子教授模型,以新颖的方式组合不同的感官。
对比之下,GPT-4o并不完美,但一般都是正确的。
而谷歌呢?
Jim Fan老师不愧为老冲浪选手,他说,谷歌做对了一件事,“他们终于开始努力将人工智能集成到搜索框中”。
也有网友真的开始了谷歌新发布的Projectt。 Astra,发横向评价视频:
我们听了内容。一般来说,他个人觉得谷歌新闻发布会上的演示展示环节不是很好。他和其他三个人去摊位试用了演示 Astra,只能玩2分钟左右。
玩下来的感觉,就是大写的“谷歌打的是一场没有准备好的战斗”。
在他面前的测试玩家让Projectt Astra对一件事讲了一个故事,Astra发誓要答应,然后就没有了...
但是让Astra识别出画出来的帆船和笑脸,它还是可以胜任的。
相比之下,他认为GPT-4o更丝滑,但由于他还没有自己开始GPT-4o,所以没有多少妄作评价。
在每个人的试玩狂欢节中,还有一件戏剧性的事情。
那就是XAI的Grok,马斯克的大型公司,正确地回答了Ilya离开公司的问题。
OpenAI本身的大模型没有提供正确的响应。

网友故意郑重宣布:
突发事件!Grok1xAI.0击败OpenAI新推出的GPT-4o。
当然,这必须归功于XAI背后有推特(X)没有什么比实时数据/帖子/新闻更快、更丰富、更真实的了。
另一个有趣的是,Hacker 大家在News上发起了一个神奇的讨论。
有人展示了一个链接,跳转的是2021年发布的打油诗数据集Needle in a Needlestack(只能说世界之大无奇不有),说他坚信GPT-4o训练时,使用了里面的数据,

原因是这样的——
Needle in a Needlestack用于衡量大模型对上下文窗口信息的关注,包括数千首油诗的提示,提示询问一首油诗在特定位置的问题。
简单来说就是一个有趣版本的大海捞针。
然而,目前还没有人的大模型在这次测试中表现出色。
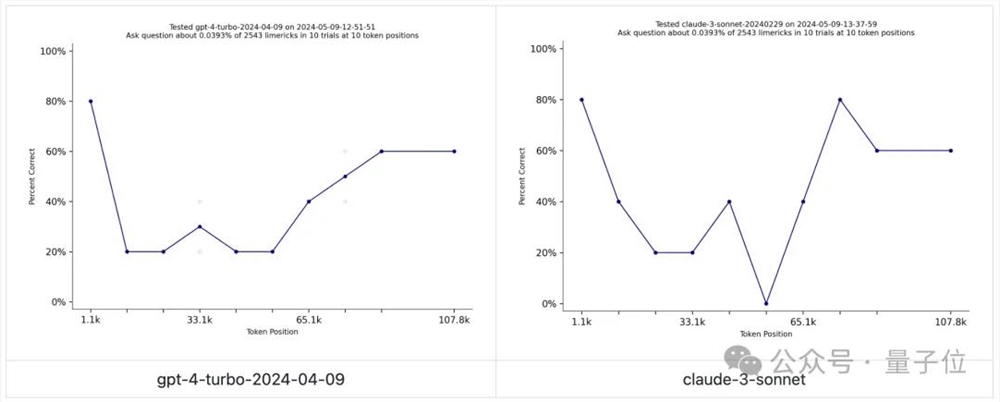
然而,GPT-四o取得了突破!
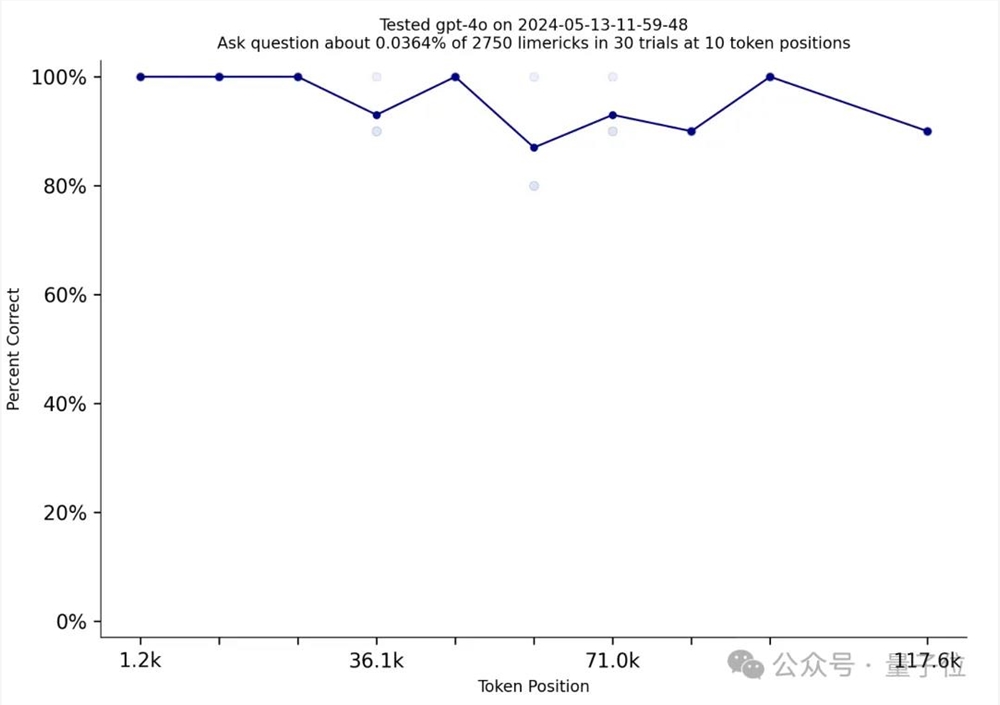
这是一种接近完美的表现。
于是网友们开始热情讨论OpenAI做了什么,让GPT-4-Turbo的表现从GPT-4-Turbo大幅跃升。
就像贴主所说的,最重要的观点,绝对OpenAI使用Needlele in a Needlestack是为了训练自己,否则团队会出来解释数据集背后的解释。如何检查并确保数据集不被任何大型模型用于训练?
当然,也有人发出了以前的声音(我们在3月份参加了月亮的秘密新闻发布会,上海人工智能实验室的领导科学家林大华也听到了类似的演讲):
大海捞针试验对模型的实际长上下文功能了解非常有限。
它之所以被广泛使用,是因为早期模型在这方面表现不佳,容易测试。
其实大部分都是最新这个模型现在在这个任务上做得很好。
不过这次信息增量增加了一点,很多人认为大模型在执行32k以上。 在tokens的长上下文中,任何复杂操作的能力都会大大降低。

最后,OpenAI真的是人干事?
在谷歌 I/O 开发者大会前贴脸输出GPT新功能,谷歌新闻发布会结束后立即带来重磅消息。沉默了半年的OpenAI首席科学家Ilya,真的像大家猜测的那样正式宣布离职。
好消息:
Ilya还活着。
坏消息:
谷歌,你一点流量都摊不上...
Copyright © 2013-2025 bacaiyun.com. All Rights Reserved. 八彩云 版权所有 八彩云(北京)网络科技有限公司 京ICP备2023023517号
本站文章全部采集于互联网,如涉及版权问题请联系我们删除.联系QQ:888798,本站域名代理为阿里云
